Problems and impacts correlation management¶
What is this correlation ?¶
The main role of this feature is to allow users to have the same correlation views in the console than they got in the notifications.
From now, users won”t get notified if there was a dependency problem or example (a host in DOWN make the service notifications to not be send for example). But in the console, we still got some green and red indicators: the scheduler waited for actual checks to put the elements in a UNKNOWN or UNREACHABLE state when he already know that there was a dependency problem.
Now it”s smart enough to put such states to elements that we know the check will fail. An example?
Imagine such a parent relations between hosts:
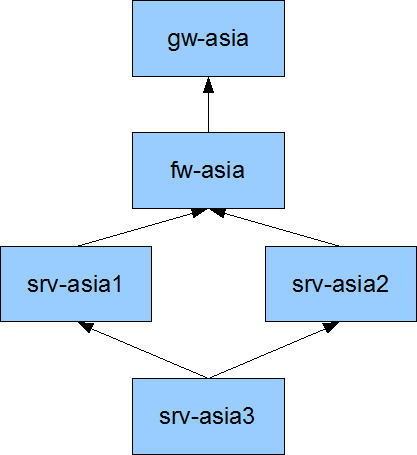
If gw is DOWN, all checks for others elements will put UNREACHABLE state. But if the fw and servers are checks 5 minutes later, during this period, the console will still have green indicators for them. And are they really green? No. We know that future checks will put them in errors. That why the problems/impacts feature do: when the gateway is set in HARD/DOWN, it apply a UNREACHABLE (and UNKNOWN for services) states for others elements below. So the administrators in front of his desk saw directly that there is a problem, and what are the elements impacted.
It”s important to see that such state change do not interfere with the HARD/SOFT logic: it”s just a state change for console, but it”s not taken into account as a checks attempt.
Here gateway is already in DOWN/HARD. We can see that all servers do not have an output: they are not already checked, but we already set the UNREACHABLE state. When they will be checks, there will be an output and they will keep this state.
How to enable it?¶
It’s quite easy, all you need is to enable the parameter
enable_problem_impacts_states_change=1
See the page Main advanced configuration <configuringshinken-configmain-advanced> for more information about it.
Dynamic Business Impact¶
There is a good thing about problems and impacts when you do not identify a parent devices Business Impact: your problem will dynamically inherit the maximum business impact of the failed child!
Let take an example: you have a switch with different children, one is a devel environment with a low business impact (0 or 1) and one with a huge business impact (4 or 5). The network administrator has set SMS notification at night but only for HUGE business impacts (min_criticity=4 in the contact definition for example).
It’s important to say that the switch DOES NOT HAVE ITS OWN BUSINESS IMPACT DEFINED! A switch is there to server applications, the only business impact it gets is the child hosts and services that are connected to it!
- There are 2 nights:
- the first one, the switch got a problem, and only the devel environment is impacted. The switch will inherit the maximum impact of its impacts (or it own value if it’s higher, it’s 3 by default for all elements). Here the devel impact is 0, the switch one is 3, so its impact will stay at 3. It’s slower than the contact value, so the notification will not be send, the admin will be able to sleep :)
- the second night, the switch got a problem, but this time it impacts the production environment! This time, the computed impact is set at 5 (the one of the max impact, here the production application), so it’s higher than the min_criticity of the contact, so the notification is send. The admin is awaken, and can solve this problem before too many users are impacted :)